

主要
The Hitchhiker's Guide to the Galaxy 中的 Babel Fish 是一个虚构的工具,可以在两种语言之间进行翻译。在以日益增长的互连性和移动社交性为特征的当代全球格局中,实现这些技术并促进数字和物理世界中的按需语音到语音转换 (S2ST) 的社会迫切性从未如此强烈。尽管语音在日常交流中处于中心地位,但今天的机器翻译 (MT) 系统仍然以文本为导向。有关为什么在 MT 中应优先考虑语音的更多详细信息,请参阅补充信息第 I.1 节。尽管单一的单峰模型,例如 No Language Left Behind (NLLB)6将文本到文本翻译 (T2TT) 覆盖范围推送到 200 多种语言,统一的 S2ST 模型远未达到类似的范围或性能。这种差异可能归因于许多原因,但音频数据稀缺和建模限制仍然是主要障碍。
现有的 S2ST 系统有三个主要缺点。首先,这些系统往往专注于高资源语言,而将许多低资源语言抛在后面。其次,这些系统主要服务从源语言到英语 (X-eng) 的翻译,而不是相反的 (eng-X)。第三,大多数 S2ST 系统严重依赖多个子系统的级联;例如,自动语音识别 (ASR) + T2TT + 文本转语音 (TTS)。尽管存在直接系统1,4,5时,它们的性能与级联对应项的性能不匹配7.有关当前技术形势的更多详细信息,请参阅补充信息第 I.2 节。
为了解决这些限制,我们引入了 SEAMLESSM4T(Massively Multilingual and Multimodal Machine Translation),这是一个支持 ASR、T2TT、语音到文本翻译 (S2TT)、文本到语音转换 (T2ST) 和 S2ST 的统一系统。为了构建这一点,我们使用新的句子嵌入空间(句子级多模态和语言不可知表示,或 SONAR)创建了一个超过 470,000 小时的自动对齐语音翻译 (SEAMLESSALIGN) 语料库8.然后,我们将该语料库的过滤子集与人工标记和伪标记数据相结合,开发了第一个多任务系统,该系统将 S2ST 从 100 多种语言执行到 36 种语言,将 S2TT 和 ASR 执行到 96 种语言,将零样本 T2ST 执行到 36 种语言,以及执行 96 种语言的 T2TT(语言覆盖率的比较概述和补充信息第 II 部分见表 1了解更多详情)。由于 SEAMLESSM4T 的统一架构(图 D)。1) 时,该模型可以零点方式对非英文方向 (X–X) 执行 T2TT、S2TT 或 S2ST。它还可以执行 T2ST,而无需针对此任务进行明确训练。由于在大量未标记的语音数据上对 SEAMLESSM4T 的语音编码器进行了预训练(参见“无监督语音预训练”部分),它可以处理混合两种或多种语言的话语。
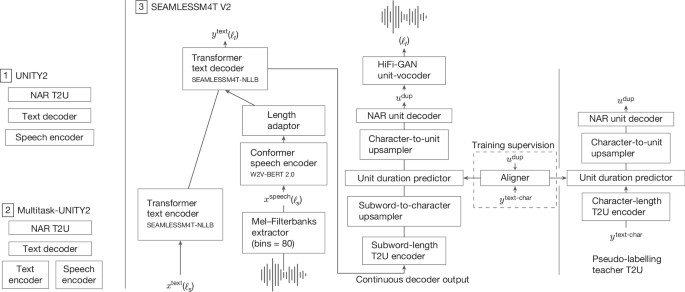
UNITY2 (S2ST 微调) 及其非自回归 (NAR) T2U 的三个主要块显示在左上角。Multitask-UNITY2 及其附加文本编码器显示在左下角。SEAMLESSM4T-V2(多任务 UNITY2 模型)的组件细分显示在右侧,侧面板显示了用于伪标记 (M4) 的教师 T2U 模型。
为了评估我们模型的输出质量,我们使用了跨越任务和模式的几个现有指标,以及四个主要的评估数据集。例如,我们使用 chrF2++9用于 T2TT、BLEU10用于 S2TT、ASR-BLEU5用于 S2ST 和 WER 用于 ASR。有关详细信息,请参见补充表 2。我们还使用 MULTILINGUAL HOLISTICBIAS 数据集测试了我们的模型对背景噪音或说话者变化的弹性,以及负责任部署的其他方面,例如性别偏见,或使用新的基于语音的指标(ASR-ETOX 和 MuTox)增加了毒性。我们在训练时通过过滤策略和推理时的光束过滤策略来减轻额外的毒性11.
除了建立SEAMLESSM4T,我们还讨论了我们工作的社会影响,以及它如何有助于提高世界就绪度12从长远来看(参见“社会影响和结论”部分)。为了促进未来的研究,我们将数据工具、代码和两种大小的 SEAMLESSM4T 模型公开用于非商业用途。
在后续部分中,我们将跟踪开发 SEAMLESSM4T 模型的关键结果。首先,我们概述了我们挖掘对齐语音和文本数据的努力,从语音语言识别开始,到使用与模态无关的编码器挖掘对齐的语音和文本片段。接下来,我们报告部分使用上述自动对齐语音数据训练的直接翻译系统的主要结果。这些结果突出了 SEAMLESSM4T 模型的任务多功能性,在 ASR、T2TT、S2TT 和 S2ST 中实现了多语言最先进的性能。然后,我们通过人工评估分析来支持报告的结果。最后,我们描述了我们为减轻增加的毒性所做的努力,并评估了我们的模型对性别差异的稳健性。
数据
训练语音翻译系统需要标记数据;即 Speech-to-Text 和 Speech-to-Speech 对齐数据。但是,对于资源匮乏的语言,这些资源非常有限。我们建立在 SONAR 的多语言和多模态嵌入空间之上8以及大量原始语音和文本,如方法中所述,用于自动挖掘对齐资源,补充现有的人工标记和伪标记数据。
语音语言识别
处理来自 Web 的原始语音涉及将话语分割成较短的块,然后进行语言识别。基于基于 VoxLingua107 和 ECAPA-TDNN 架构训练的开源模型构建13,14 元,我们开发了一种新的基于语音的语言识别 (LID) 模型,涵盖了这项工作中的所有 100 种语言(有关详细信息,请参阅方法,“音频处理和语音 LID”)。
为了衡量 LID 模型的精度和召回率,我们在扩展数据表 1 中报告了测试数据的 F1 分数。给出了 100 SEAMLESSM4T语言(总体)和 SEAMLESSM4T 和 VoxLingua107(交集)之间的 79 种常用语言的结果。请注意,VL107HF 的所有语言的 macro-F1 都较低,因为此模型未涵盖 21 种语言。我们发现,对其他语言的训练会略微降低公共语言集的整体性能,这是接近语言数量较多的直接结果。例如,祖鲁语 (zul) 经常与 Nyanja (nya) 混淆,伊博语 (ibo) 与约鲁巴语 (yor) 混淆,现代标准阿拉伯语 (arb) 与摩洛哥阿拉伯语 (ary) 和埃及阿拉伯语 (arz) 混淆。我们的模型提高了 17 种语言的分类准确率(F1 差异大于 5%),在不计算新覆盖的语言的情况下,平均提高了 14.6%,同时降低了 12 种语言的分类准确率(平均损失 9.8%)。我们通过在 LID 分数 (可能性) 上应用阈值来进一步过滤数据。已调整特定于语言的阈值,以最大化开发数据的 F1 分数。通过过滤掉 8% 的数据,我们能够将 F1 分数进一步提高近 3%。
SONAR 文本嵌入空间
为了从语言识别的句段中挖掘自动对齐的翻译数据,我们依赖于与语言和模态无关的编码器。为此,我们构建了 ref 中开发的 SONAR 嵌入空间。8.目前,我们提供适用于 200 种语言的单个文本编码器和解码器,以及适用于 37 种语言的语音编码器。200 种语言的列表与 NLLB 项目的语言列表相同6.在多语言相似性搜索中,xsim 和 xsim++15是两个众所周知的代理指标,用于评估多语言嵌入空间以进行挖掘。如表 2 所示,SONAR 的性能大大优于 LASER3 等其他常用方法16或 LaBSE17使用较低的 xsim 和 xsim++。
此外,我们还评估了 SONAR 文本编码器和解码器在 T2TT 任务上的应用。尽管 SONAR 中的编码器-解码器注意力被瓶颈固定大小的嵌入所取代,但与中型 NLLB 密集模型相比,超过 200 种语言的平均性能具有竞争力(参见扩展数据表 2 的 T2TT 列)。这一结果证明,使用 attention 并不是合理翻译准确性的必要条件。有关 SONAR 的更多详细信息,请参阅 D2。
训练语音编码器
语音编码器仅使用教师-学生方法进行语音转录训练(参见方法,“SONAR”)。在端到端循环中评估每个语音编码器的迭代,即挖掘和训练 S2TT 或 S2ST 翻译系统,将是计算密集型的。相反,我们将语音编码器与 SONAR 文本解码器连接起来,并评估了这个零样本 S2TT 系统作为编码器质量的代理。如扩展数据表 2 的 S2TT 列所示,SONAR 语音编码器与 FLORES 上的 WHISPER-LARGE-V2 等模型相比具有优势6和 FLEURS18数据集,该数据集是在大量监督数据上进行训练的。在一些资源丰富的语言(如德语、俄语或葡萄牙语)中可以观察到准确性的差距,但在斯瓦希里语或孟加拉语等几种资源丰富的语言中,SONAR 的性能优于 WHISPER-LARGE-V2(见补充表 8)。
无缝对齐
SONAR 文本和语音编码器用于挖掘三种类型的对齐数据:(1) 英语语音到非英语文本 (Sen2Txx);(2) 非英语语音转英语文本 (Sxx2Ten);(3) 非英语语音到英语语音 (Sxx2Sen)。SEAMLESSALIGN 在 Sen2Txx 中提供 202,796 小时的音频,在 Sxx2Ten 中提供 239,767 小时的音频,在 Sxx2En 中提供 29,161 小时的音频。这些对齐数据是从总共 2.5M h 的原始音频(其中英语占近 40%)中挖掘出来的。SONAR 语音编码器在 43,772 小时的监督 ASR 数据上进行了训练。有关每种语言的统计数据,请参阅补充表 8。
对于文本域,我们使用 NLLB 项目整合的相同数据6.数量从马耳他语或斯瓦希里语等资源匮乏语言的 3300 万或 5500 万个句子到 220 亿个英语句子不等。
除了马耳他语之外,我们只能访问少量的原始音频,我们能够挖掘超过 100 小时的语音与所有语言的英语语音对齐。大多数语言与英文文本的对齐时间达到 1000 小时,而高资源语言的对齐时间超过 10,000 小时。总体而言,SEAMLESSALIGN 涵盖 37 种语言,总时长为 470,000 小时。
添加如此大量的数据来训练多语言翻译系统是一项巨大的计算挑战。如方法“建模”中所述,并非所有这些数据都用于建模,而只用于 SONAR 对齐分数最高的子集。由于我们挖掘的数据可以帮助支持许多不同的用例,因此我们开源了指导其重建所需的元数据(最高 SONAR 阈值为 1.15;请参阅方法,“SpeechAlign”),以允许社区重建 SEAMLESSALIGN 并将其用于自己的目的。因此,可以根据任务调整最佳阈值,从而平衡数据集大小和对齐质量。我们的挖矿代码在 STOPES 库中也是开源的。
多任务翻译系统建模
将方法“建模”中概述的建模技术与来自 SEAMLESSALIGN 的其他数据(参见方法,“数据”)相结合,我们训练了两种规模的SEAMLESSM4T模型:具有 2.3B 参数的大型和具有 1.2B 参数的中型模型。SEAMLESSM4T-MEDIUM 旨在成为一个可访问的测试平台,用于微调、改进或进行分析。我们进一步训练了大型SEAMLESSM4T的改进版本,称为 SEAMLESSM4T-V2,具有更好的语音编码器(参见方法,“无监督语音预训练”)和更强大的单元解码器(参见“S2ST 微调”部分)。所有 SEAMLESSM4T 模型在文本模态中支持 96 种源语言,在语音模态中支持 100 多种源语言。在目标端,模型可以输出 96 种语言的文本形式和 35 种语言的语音形式。补充表 12 和 13 中详细说明了每个方向和每个源(例如 M4 或 SEAMLESSALIGN)的受监督数据量。这表明,对于某些平移方向,并且由于缺乏监督数据,我们的模型将被评估为零。
我们评估了我们的模型在所有四个监督任务(T2TT、ASR、S2TT 和 S2ST)以及文本到语音翻译的零样本任务(T2ST,也称为跨语言文本到语音合成)上19).为了生成文本假设,我们使用 beam-search 进行解码。我们使用 chrF2++ 对 T2TT 和 BLEU 对 S2TT 进行评分。我们使用 SacreBLEU 测量 BLEU 分数,并在补充表 2 中提供签名。对于 ASR,我们在 ref 之后的标准化转录和参考文献上使用 WER(单词错误率)进行评分。20.
在 S2ST 和 T2ST 推理期间,我们执行了两遍波束搜索解码;第一遍解码中的最佳假设嵌入到文本解码器中,并被发送到文本到单元模块(T2U;参见“S2ST 微调”部分)以搜索最佳单元序列假设。我们对两个检索都使用了 beam width 5。我们使用 WHISPER 模型评估了 ASR-BLEU 的 S2ST 和 T2ST 准确性。我们将 WHISPER 的解码温度设置为零,并使用贪婪解码来确保 ASR 模型的确定性行为。转录的假设以及参考文献在 ref 之后进行标准化。20在计算 BLEU 分数之前。
与语音翻译的级联方法的比较
在 SEAMLESSM4T 和 WHISPER 支持的语言集上,我们在表 3(S2TT 列)中比较了直接 S2TT 模型与级联模型的性能,即 WHISPER ASR 模型和 NLLB T2TT 模型的组合。SEAMLESSM4T-V2 在 X-eng 方向上比具有小于 3B 参数的级联模型高出 4.6 BLEU点(从 22.0 到 26.6),在 eng-X 方向上比 1 BLEU点(从 21.1 到 22.2)高出 1 个点。我们还在表 3 中添加了与大型 NLLB-3.3B T2TT 模型的级联模型。这些模型超过了 4B 参数,并且在 X-eng (+3.9) 中在很大程度上被 SEAMLESSM4T-V2 超越;它们在 eng-X 方向上仅略微比 SEAMLESSM4T-V2 高出 0.2 BLEU 个百分点。
与之前落后于级联系统的直接 S2TT SOTA 模型(例如,AUDIOPALM-2-8B-AST.21),SEAMLESSM4T-V2 比 FLEURS X–eng S2TT BLEU评分提高了 6.9 分(从 19.7 分提高到 26.6 分,即提高了 35%)。
表 3(S2ST 列)还比较了 SEAMLESSM4T 模型和级联模型之间的 S2ST。对于 S2ST,我们探索了两种级联选项:(1) 使用 ASR、T2TT 和 TTS 的三阶段,以及 (2) 使用 S2TT 和 TTS 的两阶段。这两种类型的级联系统都依赖于 TTS 模型来合成翻译后的语音,为此我们使用 YOURTTS22合成英语语音和 MMS 时23在比较的 26 种非英语语言中合成语音时(SEAMLESSM4T 的支持与 MMS 的 TTS 系统支持之间的重叠)。我们的 SEAMLESSM4T-LARGE 在 FLEURS X-eng 方向上比两级级联模型高出 8 个 ASR-BLEU 点 (17.8–25.8)。它还比更强的三级级联模型 (WHISPER-LARGE-V2 + NLLB-3.3B + YOURTTS) 高出 2.1 个 ASR-BLEU 点 (23.7–25.8)。改进后的 SEAMLESSM4T-V2 进一步加强了在 S2ST FLEURS X–eng 上的领先优势,额外增加了 +3.9 ASR-BLEU 分 (25.8–29.7)。在 CVSS 上,SEAMLESSM4T-V2 的性能比两阶段级联模型 (WHISPER-LARGE-V2 + YOURTTS) 高出 9.6 个 ASR-BLEU 点 (29.6–39.2)。在 FLEURS S2ST eng-X 方向上,我们将评估集减少到 MMS 和 SEAMLESSM4T 的 TTS 都支持的 26 种语言。中型型号 (SEAMLESSM4T-MEDIUM) 的平均 ASR BLEU得分为 15.8。SEAMLESSM4T-LARGE 的平均 ASR-BLEU 为 20.9,凭借其改进的语音编码器和非自回归 T2U 模型,SEAMLESSM4T-V2 进一步获得了 +5.2 ASR-BLEU 点 (20.9– 26.1)。相比之下,具有 MMS (WHISPER-LARGE-V2 + NLLB-3.3B + MMS) 的最佳三级级联系统的平均 ASR-BLEU 得分为 22.7,也就是说,SEAMLESSM4T-V2 比最先进的级联模型高出 15% (22.7–26.1)。
我们在补充信息部分 IV.1 中分享了 S2TT 和 S2ST 任务的评估结果以及其他指标,包括我们与模态无关的 BLASER 2.0。
多任务处理结果
我们在表 4 中报告了 ASR 和零镜头 T2ST 任务的 FLEURS 基准(X-eng 和 eng-X)以及 T2TT 的相关 FLORES 基准(X-eng 和 eng-X)的结果。在 ASR 中,SEAMLESSM4T-LARGE 的性能优于 WHISPER-LARGE-V220在重叠的 77 种支持语言上,WER 降低了 46%(从 41.7 降低到 22.6),而 SEAMLESSM4T-V2 比 WHISPER-LARGE-V2 提高了 56%(从 41.7 提高到 18.5)。我们还在补充表 9 中与 MMS 进行了比较23在 FLEURS-54 上,MMS 和 WHISPER 都支持的 FLEURS 语言子集。SEAMLESSM4T-V2 的性能比使用 CTC 评估的 MMS 变体高出 38% 以上(从 31.0 到 19.1),但被利用单语 n-gram 语言模型的变体所超越(WER 高出 5%,为 18.6)。
在 T2TT 支持任务中,表 4 中的结果表明,我们的 SEAMLESSM4T 模型与 NLLB-3.3B 相当(参考6) 在 X–eng 和 eng–X 方向上。
接下来,我们以零镜头的方式评估了 SEAMLESSM4T 模型对 T2ST 任务的影响。鉴于 FLEURS 为每个样本收集了三位不同母语人士的三份录音,我们随机选择了一份用于 T2ST 任务(输入为文本)。我们在表 4(T2ST 列)中报告了 SEAMLESSM4T 模型和级联模型之间的比较,其中 NLLB 和 YOURTTS(英语 TTS)或 MMS(非英语 TTS)用于合成翻译文本。我们在 88 个 X-eng 方向上平均了 ASR-BLEU 分数 (FLEURS 与 SEAMLESSM4T 支持的语言之间的重叠)。我们还在 26 个 eng-X 方向上对 ASR-BLEU 进行了平均(SEAMLESSM4T与 MMS 的 TTS 模型重叠)。与级联模型相比,SEAMLESSM4T-LARGE V2 的零镜头能力在 X-eng 中与 NLLB-3.3B + YOURTTS 相当,在 eng-X 中比 NLLB-3.3B + MMS 高出 +3.9 个 ASR-BLEU 分以上(从 23.7 到 27.6)。这一结果表明:(1) 零镜头 T2ST 的 SEAMLESSM4T 质量与监督任务相当,并且 (2) 非英语语音源是我们的模型翻译中最具挑战性的输入。
为了进一步了解 FLEURS S2TT X–eng 方向的改进来自哪里,我们按资源级别对语言进行了分组(参见补充表 12 中的确切语言列表),并在表 5 中报告了每个资源级别的平均 BLEU 分数。结果表明,SEAMLESSM4T 大大提高了从低资源语言翻译的质量,提高了 +10.2 BLEU(从 18.0 提高到 28.2,即比 AUDIOPALM-2-8B-AST 提高了 57%)。我们还在 AUDIOPALM-2-8B-AST 中监督的低资源方向上对 Low* 列进行平均。在该方向子集中 +7.8 BLEU 的增益表明,这种改进超出了纯粹的监督,而应归因于监督数据和训练配方的质量。
自动和人工评估
语音翻译中的语义准确性通常使用自动度量标准 BLEU 进行评估10用于 S2TT 或其扩展 ASR-BLEU 用于 S2ST。此外,我们使用 BLASER 2.0(参考24),BLASER 的扩展25,它现在支持对语音和文本进行与模态无关的评估和质量估计。
为了补充自动指标的效用,我们还依赖于对模型的广泛人工评估。在下文中,我们使用 XSTS(跨语言语义文本相似性)协议为 S2TT 和 S2ST 任务提供人工评估26和 MOS (平均意见分数) 协议,用于 FLEURS 测试集上的语音输出(参见方法,“人工评估”)。但是,由于资源限制,我们涵盖的模型数量有限(SEAMLESSM4T-LARGE、SEAMLESSM4T-LARGE V2 和级联基线,该基线由用于 ASR 的 WHISPER-LARGE-V2、用于翻译的 NLLB 3.3B 和用于 S2ST 任务的 TTS 的 YOURTTS 或 MMS 组成)和翻译方向(23 种语言从英语传入和翻译成英语,10 种语言 X-eng 用于 MOS)。
XSTS 分数显示,对于所有任务和语言方向,SEAMLESSM4T-LARGE V2 在平均语言级别 XSTS 分数和获胜率(XSTS 性能优于其评估语言的比例)方面都优于级联基线系统和 SEAMLESSM4T-LARGE,置信度高。对于 SEAMLESSM4T-V2 的相对性能最强的 S2ST 任务,与 X-eng 和 eng-X 方向的级联基线和 SEAMLESSM4T-LARGE 相比,SEAMLESSM4T-V2 的胜率接近 100%,eng-X 和 X-eng 的平均语言 XSTS 得分比级联基线高约 0.5 分,与 SEAMLESSM4T-LARGE 相比高 0.36-0.51 分, 分别。参见补充表 22 和 24,分别了解完整的语言级别和总结 XSTS 结果。
我们还使用 Mean Opinion Score 协议测量 S2ST 的语音输出质量,该协议评估 (1) 音质,(2) 语音清晰度和 (3) 自然度。我们发现,一般来说,在所有 MOS 方面,SEAMLESSM4T-LARGE V2 往往优于 SEAMLESSM4T-LARGE,后者往往优于级联模型基线,但 X-eng 除外,对于SEAMLESSM4T-LARGE 代,强烈推荐 SEAMLESSM4T-LARGE 和 SEAMLESSM4T-LARGE V2 代之间 +1 分的平均差异),这是一个意想不到的结果,可能是模型架构差异的结果,否则会提高生成质量。参见补充表 23 和 24,分别了解完整的语言级别和总结的 MOS 结果。
使用 S2ST 任务的 XSTS 评估,BLASER 2.0(在给定语言方向上所有评估项目的平均值)在 X-eng 方向(BLASER 2.0 为 0.845,ASR-BLEU 为 0.74)和eng-X 方向(BLASER 2.0 为 0.81,ASR-BLEU 为 0.246)都实现了卓越的 Spearman 相关性。类似的结果也适用于 S2TT 任务(有关完整结果,请参阅补充表 21)。
最后,我们通过基于 FLEURS 创建开放的稳健性基准,测试了我们的模型在噪声和扬声器变化方面的稳健性(参见方法,“稳健性”)。为此,我们发现,与 WHISPER-LARGE-V2 相比,SEAMLESSM4T-V2 对背景噪声和扬声器变化的弹性平均分别高出约 42% 和 66%(参见补充信息第 V.2 节中的完整结果)。
负责任的 AI
毒性
不良内容可以定义为可能煽动针对个人或群体(例如宗教、种族或性别)的仇恨、暴力或虐待的亵渎或语言。当谈到文本的大规模多语言毒性分类器时,ETOX 工具包似乎是唯一一个语言覆盖范围最大的可开放访问选项27.在语音翻译的上下文中,我们主要担心会增加毒性,即在翻译中引入源话语中不存在的毒性元素。在参考文献中评估了英语的言语毒性。28最近,MuTox 支持数十种语言29.
因此,对于语音和文本多语言毒性检测,我们使用 ETOX (或 S2ST 的 ASR-ETOX) 和 MuTox (语音和文本) 作为检测和评估增加毒性的指标。为了减轻毒性,我们实施了两种技术来处理增加的毒性。在训练之前,我们过滤掉了毒性不平衡的训练对。此外,我们使用了 Mintox11在推理时(参见方法,'毒性检测')。
我们在两个数据集(FLEURS 和 HOLISTICBIAS27) 跨越 24 个翻译方向,使用系统覆盖范围与 MuTox 交叉点的语言(Arb、Ben、cat、ces、Dan、Deu、est、Fin、fra、Hin、Ind、ITA、NLD、PES、POL、POR、RUS、SLK、SPA、SWH、TGL、TUR、URD、VIE),使用系统覆盖范围和 MuTox 交叉点上的语言(请注意,MuTox 的语言覆盖范围更广,类似于 SONAR、 但它只用 30 种语言进行了基准测试29).请参阅补充信息第 VI.1 节中使用 ETOX 评估的更多翻译方向的结果。表 6 显示,尽管增加毒性的水平和类型因语言和数据集而异,但我们系统中增加的毒性在我们的两个毒性检测指标中具有相对较低的患病率 (<0.4%)。表 6 显示 MinTox 能够始终如一地减轻增加的毒性。使用 SEAMLESSM4T-V2 + MinTox 始终获得所有模式、方向和数据集的最低毒性,与不使用 MinTox 的相同模型相比,MuTox 的毒性降低高达 5%(ETOX 的毒性降低高达 80%),与基线相比,MuTox 的毒性降低高达 20%(ETOX 的毒性降低高达 90%)(参见补充信息第 VI.1 节中的完整结果)。
性别偏见
母语背景下的性别偏见可以定义为语法性别确定中的错误。这种偏见可能明确表现为在将非性别形式翻译成有性别形式时对一种性别的过度概括(例如,输出偏向于男性的表现),或者在改变仅在性别变化不同的句子的翻译质量时缺乏稳健性。
以前关于这个问题的工作主要是在文本模态中30、31、32 元并且往往以英语为中心,几乎没有人口统计轴和多语言参考。针对语音模式的类似努力仍然很少33,34 元.
我们使用了 MULTILINGUAL HOLISTICBIAS35及其语音扩展来比较 S2TT 和 S2ST 的性能。eng-X 方向可以在存在男性或女性参考的情况下比较表现,而 X-eng 方向可以在我们改变性别屈折时在翻译中进行稳健性比较。英语-西班牙语对的一个典型例子是“I'm a homemaker”以及相应的西班牙语翻译“Soy amo de casa”和“Soy ama de casa”。当从英语翻译成西班牙语时,我们可以测量系统是否过度泛化到一种性别,而在另一个方向上,我们可以评估翻译到性别屈折的稳健性(参见方法,“多语言整体偏见的语音扩展”)。
我们对 S2TT 和 S2ST 的翻译偏倚进行了一系列综合评估(平均结果见扩展数据表 3,详细结果见补充信息第 VI.2 节)。SEAMLESSM4T-V2 始终提高了跨指标和任务的性别变化的稳健性。与以前的型号相比,SEAMLESSM4T-V2 在 S2TT 中比 SEAMLESSM4T-LARGE 提高了 0.4%,在 S2ST 中比 BLASER 2.0 提高了 0.1%,并且在 S2TT 中比 WHISPER-LARGE-V2 (+YOURTTS) 高出 0.1%,在 S2ST 中比 BLASER 2.0 高出 0.9%。然而,与之前的模型相比,SEAMLESSM4T-V2 在性别过度泛化方面无法持续改善。SEAMLESSM4T-V2 在 BLASER 2.0 和 SEAMLESSM4T-LARGE 方面相当,但在 ASRchrf 方面远远落后(2.2%),并且在 S2TT 方面过度泛化增加了 0.2%。尽管我们可以通过提高模型的整体质量来提高偏差稳健性,但我们似乎需要特定的技术来抵消模型对特定性别的过度概括。
社会影响和结论
我们生活的世界从未像现在这样相互联系——互联网、移动设备、通信平台和社交媒体的全球普及使个人接触到比以往更多的多语言内容36.当前的社会秩序对一个人的世界准备提出了要求12,这是衡量一个人在多语言世界中的能力的衡量标准。世界就绪性最初是在语言学习的背景下开发的,它强调了出于工具性(即就业或学校教育)和文化原因(即成为全球公民)能够用母语以外的语言进行交流的重要性。也就是说,尽管我们认为语言习得应该仍然是提高我们的世界准备的关键机制,但我们承认这样做需要许多人可能不具备的资源。
SEAMLESSM4T 支持的下游应用程序可以通过简化各种上下文之间的多语言交换,允许按需访问全球通用性。SEAMLESSM4T 支持的应用程序可以充当 co-piloting 机制,支持用户进行多语言对话,并增强他们对语音密集型交互的信心。随着基于语音的界面(例如,音频助手、语音备忘录和实时转录)和听觉内容(例如,播客、有声读物和短视频)变得越来越普遍,支持 SEAMLESSM4T 的下游应用程序可以解锁更多种类的多语言体验。
从包容性的角度来看,SEAMLESSM4T 对多模态的关注可能会在增强那些有无障碍需求的人和那些可以用多种书写系统转录语言的人的世界就绪性方面产生有意义的影响。对于许多缺乏阅读或写作技能或无法依赖视力的人(即盲人或有视力障碍的人)来说,语音辅助技术对于他们的交流和保持联系至关重要37.翻译语音的能力使这些群体不仅能够更全面地获取母语之外的信息,而且能够以更适合其交际需求的方式获得信息。
与大多数技术一样,收益分配因用户人口统计和社会状况而异38.尽管我们提出 SEAMLESSM4T 可以通过降低跨语言交流的障碍来增强全球就绪性,但一些用户在使用我们的工作时可能会遇到比其他用户更多的困难。例如,与许多其他语音技术类似,SEAMLESSM4T 的 ASR 性能可能因性别、种族、口音或语言而异39,40 元.此外,我们的系统在翻译俚语或专有名词方面的性能在高资源语言和低资源语言之间也可能不一致。
S2ST 面临的另一个挑战是,与书面语言相比,语音往往更依赖于即时接收和反馈。换句话说,说话人在确定输出质量或在实时对话中进行编辑的能力受到限制。如果没有在回译或母语人士的帮助下进行计划和修改的能力,S2ST 在误译或毒性方面可能会带来更高程度的交互风险。我们敦促使用 SEAMLESSM4T 微调或构建工件的研究人员和开发人员批判性地思考可以帮助用户规避这些潜在障碍的设计功能。重要的是,我们认为,最好将 SEAMLESSM4T 驱动的应用程序视为协助翻译的增强设备,而不是取代对语言学习或可靠人工口译需求的工具。此提醒在涉及法律或医疗决策的高风险情况下尤其相关。
最后,语音不是口语文本——它包含了一套值得进一步研究的韵律(例如,节奏、重音、语调或语气)和情感成分41.为了创建感觉有机和自然的 S2ST 系统,应该将更多的研究集中在保留表现力的输出生成上42.此外,Babel Fish 的完美实现需要对低延迟语音翻译的研究进行更深入的投资。开发支持流式处理的系统(即在呈现输入句子时逐步翻译输入句子)可能会增加这些系统在机构环境中的采用43,44 元.我们希望SEAMLESSM4T为这两个研究领域开辟新的可能性。
方法
数据
开发有效的多语言和多模态翻译系统(例如 U SEAMLESSM4T)需要跨语言和模态的大量资源。一些人工标记的翻译资源是免费提供的,但通常仅限于一小部分语言或非常特定的领域。众所周知的示例是并行文本集合,例如 Europarl45和联合国语料库46.一些人工创建的集合也涉及语音模态,例如 CoVoST47,48 元和 mTEDx49.然而,目前没有开放数据集与 WHISPER 等计划中使用的数据集的大小相匹配20或 USM50,事实证明,这解锁了前所未有的性能。
并行数据挖掘是作为使用封闭数据的替代方案出现的,无论是在语言覆盖率还是语料库大小方面。当今的主要方法是将来自不同语言和模态的句子编码到一个联合的固定大小的嵌入空间中,并根据相似性指标查找并行实例。然后通过对大量单语语料库进行成对比较来进行挖掘,其中相似度高于一定阈值的句子被视为互译51,52 元.这种方法最初是使用多语言 LASER 空间引入的53.然后,通过师生培训将这种方法扩展到 200 种语言6,16以及随后的语音模态54,55 元.
音频处理和语音 LID
我们从 400 万小时的原始音频开始,这些原始音频来自一个公开可用的爬取 Web 数据存储库,我们对其应用了多项清理和筛选操作。为了最大限度地提高挖掘的召回率,所有区段都必须具有相似的粒度。对于文本域,句子通常是定义明确的。这对于原始语音来说不太明显,因为停顿不一定用在句子边界。首先,我们使用了一个开放的语音活动检测模型56将音频文件拆分为较短的段落。其次,将新开发的语音 LID 模型应用于每个片段。我们的模型遵循 ECAPA-TDNN 架构13并扩展了在 VoxLingua107 上训练的开源模型14新增 15 种语言。最后,我们应用了一种过度分割方法,同时提出了多个可能重叠的语音分割。我们依靠挖矿方法来调整最有可能的那些。补充图1 显示此管道。
声纳
SONAR 文本和语音编码器是在参考文献中开发的。8使用两步方法(补充图 D)。首先,仅针对文本模态学习了大量多语言表示。然后,使用师生训练将嵌入空间扩展到语音模态。文本嵌入空间采用编码器-解码器方法进行训练,使用多个目标的组合:句子嵌入空间中的翻译、去噪自动编码和均方误差 (MSE) 损失目标。训练数据与用于训练 NLLB 模型的数据相同6,即将数据并行到 200 到 200 种语言的翻译。语音编码器仅在 ASR 数据上进行训练,并按照 ref 将语言分组为语言谱系组。16,例如,意大利语、普通突厥语或印度-伊朗语。为了获得最佳性能,我们分别确定了每种语言的最佳收敛性(即何时停止训练)。这为每种语言生成了一个单独的语音编码器。补充表 8 中提供了每种语言的可用 ASR 数据量。语音编码器是使用 w3v-best 2.0 语音前端初始化的。前面的工作对语音前端的输出状态执行了最大池化或均值池化,以获得语音信号的固定大小嵌入54,57 元.消融研究表明,使用三层变压器解码器可以获得更好的结果8.师生培训包括最大限度地减少 ASR 文本转录嵌入方面的 MSE 损失。这些嵌入是由 SONAR 文本编码器获得的,该编码器保持不变。没有使用翻译(翻译成英文)。
语音对齐
我们首先计算了所有过度分割的语音片段的嵌入。对于文本域,我们使用了与 NLLB 项目完全相同的文本6并将它们嵌入到 SONAR 编码器中。使用 FAISS 工具包可以有效地执行详尽的成对比较58.相似性是通过参考文献中首次引入的边距标准来衡量的。52:
(1)
其中 x 和 y 是源句子和目标句子,NNk(x) 表示另一种语言中 x 的 k 个最近邻。我们将 k 设置为 16。
例如,这相当于将 10 万小时的语音与超过 200 亿个英语句子进行比较,从而产生大约 8000 小时的对齐阿拉伯语语音。
造型
SEAMLESSM4T模型依赖于我们的多任务 UNITY 架构。我们提议的统一翻译模型建立在原版 UNITY 之上59,一个两遍解码框架,首先生成文本,然后通过预测离散声学单元来生成语音(请参阅“多语言离散声学单元”部分)。与原版 UNITY 模型相比59,(1) 在 UNITY 中从头开始初始化的核心 S2TT 模型被替换为支持文本作为输入并经过预训练以共同优化 ASR、S2TT 和 T2TT 的任务的 X2T 模型(参见“X2T 微调”部分),以及 (2) 浅层 T2U 模型(在参考文献中称为 T2U 单元编码器和第二通单元解码器。59) 替换为更深入的基于 transformer 的编码器-解码器模型,该模型具有六个在 ASR 数据上预训练的 transformer 层(参见“S2ST 微调”部分)。UNITY 的改进版本,称为 UNITY2,用新的非自回归 (NAR) T2U 解码器取代了自回归 T2U。此 NAR T2U 模型提供了更高的准确性,因为它从子词到字符,然后到单位的分层上采样。
X2T 的预训练产生了更强大的语音编码器和更高质量的首次通过文本解码器,而 T2U 模型的缩放和预训练使我们能够更好地处理多语言单元生成而不会受到干扰。此外,切换到非自回归 T2U 解码将 S2ST 推理速度提高了三倍。
多语言离散声学单元
最近的工作通过使用自监督离散声学单元作为构建直接语音翻译模型的目标,实现了最先进的翻译性能5,60 元.这包括将 S2ST 问题分解为语音到单元的翻译步骤和单元到语音的转换步骤。我们使用 XLS-R 提取连续语音表示61并将这些表示映射到离散标记。离散标记集(也称为单位词汇表)是通过将 k-means 算法应用于一组多语言音频样本来学习的。k-means 质心类似于用于将 XLS-R 语音表示序列映射到质心索引或声学单元序列的码本。我们使用了 K = 10,000 的单元词汇表大小,其中包含 XLS-R-1B 第 35 层的特征,以表示 35 种支持的目标语言。
对于单元到语音的转换步骤,我们遵循 ref。62并从学习的多语言单元构建了一个用于语音合成的多语言声码器。此模型负责从 SEAMLESSM4T 模型将预测的一系列单元合成音频。
无监督语音预训练
使用未标记的语音音频数据进行自我监督的预训练是利用未标记数据的实用方法。通过预训练,我们可以引导翻译模型的质量并充分利用我们的监督配对数据。我们根据改进的 W2V-BERT 2.0 预训练了语音编码器。它遵循 w2v-BERT63将对比学习与掩蔽预测学习相结合。W2V-BERT 2.0 使用更多的码本和额外的使用随机投影量化器的掩蔽预测任务64(RPQ) 的我们的 W2V-BERT 2.0 模型首先在 100 万小时的开放语音音频数据上进行了训练,这些数据涵盖超过 143 种语言。它遵循 w2v-BERT XL 架构63,它有 24 个 Conformer 层65和大约 6 亿个模型参数。对于 v2 版本,我们将未标记数据量从 100 万小时扩展到 450 万小时音频。最新且公开可用的多语言语音预训练模型是 MMS23.它只接受了 50 万小时的训练,涵盖 1400 多种语言。规模最大的模型是 USM50.它是一个专有的多语言语音预训练模型,具有 1200 万小时的数据,涵盖 300 多种语言。
文本到文本的翻译模型
我们 SEAMLESSM4T 模型的文本处理组件针对文本到文本翻译的任务进行了预训练,这是一项比语音翻译资源更多的任务。例如,考虑英语-意大利语方向,这是 T2TT 中资源丰富的对之一,拥有超过 1.28 亿个平行句子 - 只有 200 万对英语文本与意大利语音频配对可用于 S2TT。
训练多语言文本到文本翻译模型的一个关键步骤是使用文本分词器学习共享词汇。以下参考文献。6,我们使用了 SentencePiece66使用 BPE 算法67为此目的。NLLB-200 中使用的分词器6由于采样的伪影而缺少关键的汉字。此抽样不适用于具有大量唯一符号的徽标图形书写系统。为了解决这个问题,我们强制包含这些字符。我们的新分词器将 MTSU 前 5K 个汉字的覆盖率从 54% 提高到 84%。
为了训练我们的多语言文本转文本模型,我们在 ref 中遵循了相同的数据准备和训练管道。6使用 STOPES68.较小的语言覆盖范围使我们能够将模型的大小显著减小到 1.3B 参数,并且仅使用 95 种SEAMLESSM4T语言的 NLLB-200 训练数据。
使用伪标记进行数据增强
与任何序列到序列任务一样,语音翻译性能取决于高质量训练数据的可用性。然而,与 T2TT 或 ASR 相比,人类标记的数据量是稀缺的。为了解决标记数据的短缺问题,我们采用了伪标记69,70 元使用多语言 T2TT 模型(例如 NLLB 模型)的 ASR 数据生成伪标记的 S2TT 数据。
为了增强 S2ST 数据,通常使用 TTS 模型将文本从语音到文本数据集转换为合成语音4,5.反过来,这种合成语音被转换为离散单元进行训练。这个两步单元提取过程是一个缓慢的过程,并且考虑到对 TTS 模型的依赖性,因此更难扩展。我们规避了合成语音的需求,并在所有 36 种目标语音语言上训练了多语言文本到单元 (T2U) 模型。这些模型可以直接将文本转换为目标离散单元,并且可以在现成的 ASR 数据集上进行训练。
X2T 微调
我们的多任务 UNITY 框架的第一个关键部分是 X2T 模型,这是一个多编码器序列到序列模型,带有基于构象者的编码器65用于语音输入和另一个基于 transformer 的编码器71用于文本输入。两个编码器都使用相同的文本解码器连接并一起微调以优化 ASR、S2TT 和 T2TT 的任务。
我们的 X2T 模型包括将语音编码器 M2 的 W2V-BERT 2.0 与 M3 的文本编码器-解码器连接起来(补充图 D)。4). 对于长度适配器,我们使用了 M 适配器的修改版本72,其中我们将 Q、K 和 V 三个独立的池化模块替换为共享池化模块,以提高效率。
X2T 在带有语音音频 (x演讲) 在源语言 ⟨ls⟩,与其转录 (x发短信) 和文本翻译 (y发短信) 在目标语言 ⟨l 中t⟩. 为了实现跨模态的意义转移,X2T 模型被微调以共同优化以下目标函数:
$$\begin{array}{l}{{\mathcal{L}}}_{{\rm{S2TT}}}=-\mathop{\sum }\limits_{t=1}^{| y| }\log p(\,{y}_{t}^{{\rm{text}}}| \,{y}_{ < t}^{{\rm{text}}},{x}^{{\rm{speech}}}),\\ {{\mathcal{L}}}_{{\rm{T2TT}}}=-\mathop{\sum }\limits_{t=1}^{| y| }\log p(\,{y}_{t}^{{\rm{text}}}| \,{y}_{ < t}^{{\rm{text}}},{x}^{{\rm{text}}}).\end{array}$$
(2)
我们还优化了令牌级知识蒸馏形式的辅助目标函数 (\({{\mathcal{L}}}_{{\rm{KD}}}\)),以进一步将知识从强 MT 模型转移到学生语音翻译任务 (S2TT)。
$${{\mathcal{L}}}_{{\rm{KD}}}=\mathop{\sum }\limits_{t=1}^{| y| }{D}_{{\rm{KL}}}[p(.| \,{y}_{ < t}^{{\rm{text}}},{x}^{{\rm{text}}})\,\parallel \,p(.| \,{y}_{ < t}^{{\rm{text}}},{x}^{{\rm{speech}}})].$$
(3)
最终损失是所有三个损失的加权和:\({\mathcal{L}}=\alpha {{\mathcal{L}}}_{{\rm{S2TT}}}\,+\) \(\beta {{\mathcal{L}}}_{{\rm{T2TT}}}+\gamma {{\mathcal{L}}}_{{\rm{KD}}},\) 其中α、β 和 γ 是根据开发数据调整的标量超参数。
S2ST 微调
在微调多任务 UNITY 的最后阶段,我们使用预训练的 X2T 模型(参见“X2T 微调”部分)和预训练的 T2U 模型初始化模型,类似于在 M4 中用于伪标记 S2ST 数据的模型。用于伪标记的 T2U 模型被称为教师 T2U 模型,具有 12 个变压器层编码器-解码器。对于初始化,我们使用了一个较小的学生 T2U 模型,只有六层,以优化推理并提炼出更强的 T2U 的标签。在 SEAMLESSM4T 的第二个版本中,UNITY2 将 UNITY 中的第二遍自回归单元解码器替换为 NAR 单元解码器。我们采用了 FastSpeech2 的解码器架构73并将其扩展到离散单元生成。UNITY2 首先对 T2U 编码器输出进行分层上采样,从子字长度到字符长度,然后到单位长度。单位持续时间预测器是分层上采样的关键,在训练期间由基于 RAD-TTS 的多语言对准器进行监督74.该架构在 补充信息 第 IV.8 节中详细介绍。
我们结合使用 X-eng 和 eng-X S2ST 翻译数据对 S2ST 任务进行了微调,总计 121,000 小时。我们冻结了与 X2T 模型对应的模型权重,只微调了 T2U 组件。这是为了确保模型在前面微调阶段的任务上的性能保持不变。
自动和人工评估
巴索 2.0
BLASER 2.0 (参考24) 是 BLASER 的新版本75,它适用于语音和文本模态,因此与模态无关。与第一个版本一样,我们的方法利用了输入和输出句子嵌入之间的相似性。新版本使用 SONAR 嵌入补充信息第 III.3.1 节,支持语音中的 57 种语言和文本中的 202 种语言(在提交本文时 SONAR 覆盖的语言),并且可以扩展到共享相同嵌入空间的新语言或模态的未来编码器。为了评估语音输出(与基于 ASR 的指标不同),BLASER 2.0 提供了无文本的优势。
更具体地说,在 BLASER 2.0 中,我们获取源输入、任何 S2ST、S2TT 或 T2TT 模型的翻译输出以及参考语音片段或文本,并将它们转换为 SONAR 嵌入向量。对于 BLASER 2.0 的监督版本,这些嵌入被组合并馈送到一个小型、密集的神经网络中,该网络预测每个翻译输出的 XSTS 分数。
人工评估
除了 (ASR) BLEU 和 BLASER 2.0 等自动指标外,我们还使用了 XSTS 等人工指标26,它衡量源和目标翻译之间的语义相似性,以及标准平均意见分数(如 ITU-T P.800 建议书中的标准化,以下简称 MOS),它测量 (1) 自然度,(2) 音质和 (3) 音频生成的清晰度,以评估我们的模型。为了获得更稳健的语言级分数,我们还采用了校准集和校准方法,与评估 NLLB 模型相同6.除了 XSTS,我们还获得了 MOS 评估,以了解目标语音中音频质量的其他方面。有关人类评估方案和分析的其他信息,请参阅补充信息第 V.1 节。
鲁棒性
我们基于 FLEURS(噪声 FLEURS)构建了一个可复制的噪声鲁棒性评估基准,该基准涵盖 102 种语言、两个语音任务(S2TT 和 ASR)以及各种噪声类型(自然噪声和音乐)。为了创建模拟的嘈杂音频,我们从 MUSAN 中采样了音频剪辑76在“噪声”和“音乐”类别中,并将它们与不同信噪比 (SNR) 的原始 FLEURS 语音音频混合:10、5、0、-5、-10、-15 和 -20。我们通过 BLEU-SNR 曲线(对于 S2TT)或 WER-SNR 曲线(对于 ASR)比较了模型,这说明了当语音输入的噪声水平增加(即当 SNR 降低时)模型性能下降的程度。对于资源匮乏的语言,干净的语音设置已经很有挑战性了,更不用说嘈杂的语音设置了。因此,我们专注于属于三个不同语系的四种高资源语言(法语、西班牙语、现代标准阿拉伯语和俄语)进行噪声稳健性分析。
我们遵循了 ref.47通过使用话语级别质量指标计算平均按组平均分数和按组变异系数来评估模型对说话人变化的稳健性。我们没有使用 BLEU 作为质量指标,而是使用了 chrF,它在话语级别具有更好的稳定性。这两个稳健性指标的计算不需要明确的说话人子组标签。我们按内容(转录本)对评估样本和相应的话语水平 chrF 分数进行分组,然后计算平均按组平均分数 chrF女士和平均按组变异系数 CoefVar女士,定义如下:
$$\begin{array}{l}\,\,{{\rm{chrF}}}_{{\rm{MS}}}=\frac{1}{|G|}\sum _{g\in G}{\rm{Mean}}(g)\\ {{\rm{CoefVar}}}_{{\rm{MS}}}=\frac{1}{|{G}^{{\prime} }|}\sum _{g\in {G}^{{\prime} }}\frac{\text{标准差}(g)}{{\rm{平均值}}(g)}\end{array}$$
其中 G 是按内容(转录)和 \({G}^{{\prime} }=\{\,g| g\in G,| g| > 1,{\rm{Mean}}(g) > 0\}\) 分组的句子级 chrF 分数集。这两个指标是互补的:chrF女士提供了一个标准化的质量指标,与传统的语料库级指标不同,该指标考虑了说话人的变化,而 CoefVar女士提供扬声器变化下质量差异的标准化度量。为了进行稳健性分析,我们对测试集中至少有 40 个内容组的所有语言的 FLEURS 进行了域外评估。
负责任的 AI
毒性检测
受 ASR-BLEU 的启发,这项工作提出使用 ASR-ETOX 作为一种新的指标来检测语音中的增加毒性并评估 SEAMLESSM4T 的 S2ST 能力的增加毒性。从本质上讲,该指标遵循级联框架,首先部署标准 ASR 模块(即,与补充表 2 中定义的 ASR-BLEU 使用的模块相同),然后部署毒性检测模块 ETOX27,它使用 Toxicity-200 单词列表6.对于 S2TT,可以使用 ETOX 直接评估转换后的输出。在这两种情况(S2ST 和 S2TT)中,我们测量了话语或句子层面的额外毒性。我们首先计算了评估数据集中每个输入和相应输出的毒性检测。然后,我们比较它们,只有当输出值超过输入值时,才将一个案例算作包含增加的毒性。此外,我们使用了最近提出的 MuTox 指标,该指标可以应用于文本或语音输出,而无需 ASR。该分类器已针对 30 种语言的语音和文本毒性标记数据进行了训练。由于 MuTox 依赖于 SONAR 嵌入29, MuTox the same number of languages by the zero-shot property. However, accounting for validated quality, we report MuTox only the languages that have been benchmarked29. Again in both cases (S2ST and S2TT), we measured added toxicity at the utterance or sentence level. In this case, a sentence contains added toxicity if MuTox scores is >0.9 in the output and <0.5 in the input. We have experimentally validated these thresholds for several languages with human bilingual speakers for several pairs of languages. For S2TT, we computed MuTox in transcribed speech and target text. For S2ST, we computed MuTox in source and target speech.
For toxicity mitigation, we implement two techniques for the mitigation of added toxicity. Before training, we filter out training pairs with imbalanced toxicity. Furthermore, we use Mintox11在推理时。特别是,主工作流会生成具有不受约束搜索的翻译假设验证。然后,根据此假设运行毒性分类器。如果未检测到毒性,我们按原样提供翻译假设。但是,如果在输出中检测到毒性,我们会对输入运行分类器。如果毒性不平衡(即在输入中未检测到毒性),我们将重新运行带有缓解的转换,即 BEAMFILTERING 步骤。此 BEAMFILTERING 包括将不应出现在输出中的多标记表达式作为输入,并将它们从光束搜索假设中排除。请注意,我们不会在输入中存在毒性的情况下应用缓解措施(换句话说,我们不处理输入中存在毒性但输出毒性更大的情况)。
我们使用两个数据集来分析增加的毒性。首先,我们部署了 FLEURS 以更好地与我们的人工评估工作和这项工作的其他评估组成部分保持一致。此外,我们使用了纯英文的 HOLISTICBIAS 框架77,在以前的研究中已被证明会触发真正的附加毒性27.在这项工作中,我们通过应用 MMS 的默认英语 TTS 模型将 HOLISTICBIAS 扩展到语音23.
MULTILINGUAL HOLISTICBIAS 的语音扩展
为了比较不同模态(S2ST 和 S2TT)的性能,我们将多语言整体偏见扩展到语音23 (https://github.com/facebookresearch/fairseq/tree/main/examples/mms#tts-1)。我们将生成的 TTS 数据用作 S2TT 和 S2ST 的输入,并用作 S2ST 的参考。我们从两个方向进行了翻译:eng-X 和 X-eng。具体来说,在 X-eng 中,我们翻译了演讲的男性和女性版本。值得注意的是,一些目标语言在 SEAMLESSM4T S2ST 模型中不可用,因此我们只对 S2ST 任务的 eng-X 方向的 17 种语言进行了翻译。对于 eng-X 中的 S2TT,我们将所有语言都包含在 MULTILINGUAL HOLISTICBIAS 数据集 (n = 25) 中。作为参考,我们的实验中使用的完整语言列表可以在补充表 26 中找到。
在 S2TT 的评估指标方面,我们使用了 chrF。对于 S2ST,我们使用 ASRchrf(转录由 WHISPER-LARGE 和 WHISPER-MEDIUM 完成20分别用于 eng-X 和 X-eng,chrF 的计算方式与 S2TT 相同,只是在 S2ST 中,来自预测和参考的文本都被归一化)和 BLASER 2.0。值得注意的是,在 BLASER 2.0 上进行评估时,我们只包括 eng-X 方向的 14 种语言(arb、cat、deu、eng、fra、nld、por、ron、rus、spa、swe、tha、ukr 和 urd)(生成的 TTS 数据中的语言与我们的 S2ST 模型中可用的语言重叠)。